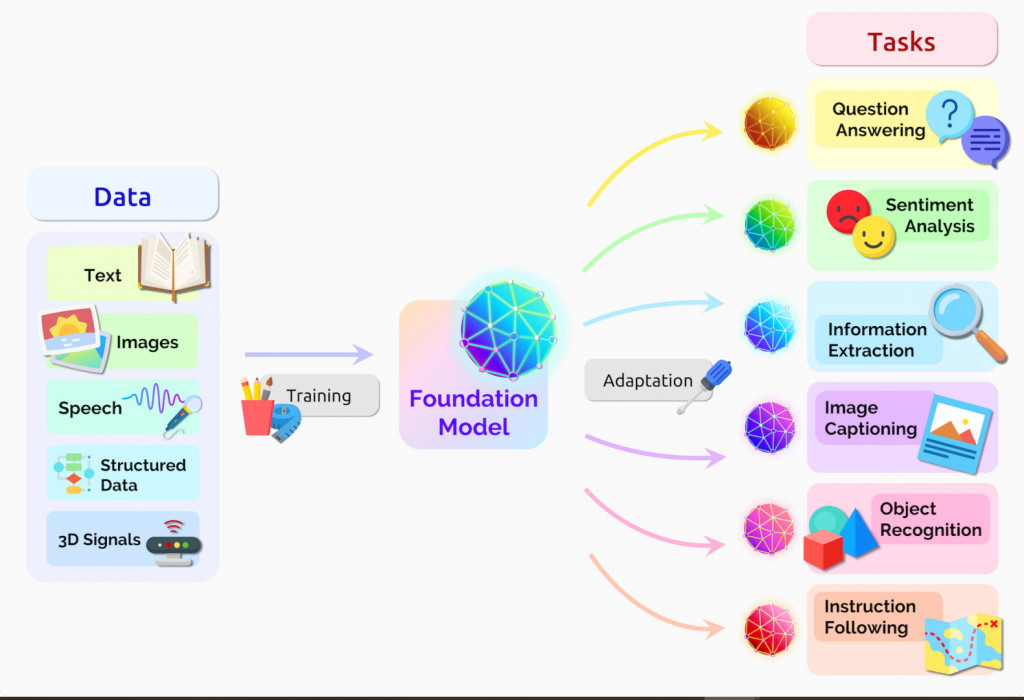
基礎模型是一種人工智慧神經網路,它通過超大規模的原始數據訓練。這些模型的關鍵特點是它們具有廣泛的適應能力,可以在多個不同的下游任務中表現優越。這些模型的規模和能力已經顯著擴展,使其成為當前人工智慧研究的主要推動力。
史丹福大學將基礎模型定義為「在大量資料(通常使用大規模自我監督學習)上訓練的模型,可以適應廣泛的下游任務。這些模型基於遷移學習(transfer learning)的標準想法、深度學習的最新進展和電腦系統的大規模應用,展現了令人驚艷的新興能力,並顯著提升了大量下游任務的性能。」
基礎模型之所以變得如此重要,一方面是因為「大即是美」的原則,即模型的性能隨著計算資源的增加而提升。這種直覺受到了大量研究的支持,並且現在有更強大的硬體和更多的資金資源可供支持。另一方面,自我監督學習等技術的普及使得模型可以在大規模數據上進行自主訓練,減少了對標記數據的需求。這些因素結合在一起,推動了基礎模型的發展,並在自然語言處理等領域帶來了一系列重要的成就。